
In my last article for The RAM Review (see link below), I introduced the Availability metric and discussed how to account for planned unavailability. Availability, Yield/Speed, and Quality are the three elements of the Overall Equipment Effectiveness (OEE) metric, which we’ve explored in previous articles (see links below). Organizations experience some combination of equipment-induced, operations-induced, and marketing-induced losses that will adversely affect Availability, Yield/Speed, and/or Quality of production.
As noted previously, Availability is the number of hours a plant or system is running divided by 8,760. Unavailability may be planned and intentional or unplanned and unintentional. Here, we’re focusing on the unplanned type and categorizing it for accurate analysis, which, in turn, can help reduce or eliminate this particular unavailability.
Click The Following Links For The Previous OEE Articles
“Lagging Metrics For Asset Management: OEE’s First Element (Availability)”
“Lagging Indicators For Asset Management: OEE (Overall Equipment Effectiveness”)
“The Reality Of ‘What Gets Measured Gets Done”
“Focus On Leading Metrics For Precision Maintenance”
When one thinks of unplanned events that adversely affect availability, equipment failures immediately come to mind. At a causal level, equipment fails because it is poorly designed, inappropriately operated, or inappropriately maintained. However, there also are some non-equipment-related reasons for unplanned unavailability of production assets. These losses are operations-induced and/or marketing induced and can affect availability, yield and/or quality of production. First, let’s examine the equipment-induced causes.
EQUIPMENT-INDUCED UNPLANNED AVAILABILITY
Unplanned equipment-induced availability losses occur when machines aren’t fit for service. To reduce these losses, we must identify the cause for the downtime-producing failures. These causal factors are summarized in Fig. 1. This week, I aml addressing items in the dark green boxes.
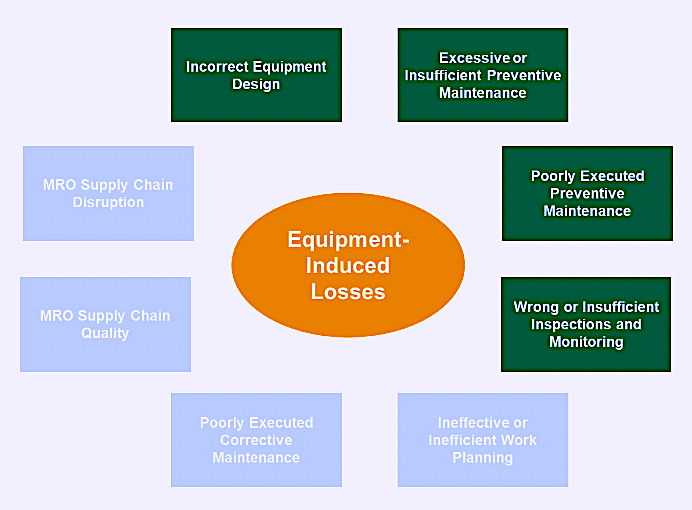
Fig. 1. Equipment-induced losses that compromise equipment availability.
♦ Incorrect Equipment Design. Design represents the “DNA,” i.e., the genetic code for reliability, of machines. Of course, reliability drives availability. Maintenance is intended to restore the reliability of equipment; it can’t alter a machine’s inherent reliability. In addition to designing for reliability, machines must be designed for maintainability, operability, flexibility, adaptability, inspectability, sustainability, and all the other “abilities” required to meet the organization’s production, safety, and environmental objectives.
♦ Excessive or Insufficient Preventive Maintenance. The purpose of preventive maintenance, as the name suggests, is to prevent failures. Common preventive-maintenance (PM) activities include lubrication, adjustments, and time-based rebuilds. When optimized and executed correctly, these types of PMs extend equipment life and assure production availability. Done incorrectly, the actions are regressive and compromise availability. For example, when greasing an electric motor, the intent is to assure that the bearings have a sufficient supply of fresh, healthy grease to help them run reliably. However, if over-greased, the excess grease passes through the motor’s inner seal, contaminates the windings, and inhibits cooling of the motor. Heat, in turn, accelerates the rate at which the stator-winding insulation degrades. Therefore, it’s important to optimize our PM planning: We want to do enough preventive maintenance to ensure equipment reliability, but we don’t want to do so much that it becomes counterproductive.
♦ Poorly Executed Preventive Maintenance. It’s not enough to make sure we apply the correct amount of preventive maintenance. The task must be executed correctly. This is where precision maintenance comes into play. Measurement-driven, precision maintenance emphasizes fit, tolerance, quantity, and quality details. For our motor-greasing example, would it be adequate to just get the regrease interval right? No, we also must be sure to apply the correct type of lubricant, with the correct performance properties; the right volume must be applied to the drive-end and non-drive-end bearings; and the lubricant must be in good condition and free of contaminants.
“Hard-time” rebuilds represent another example of a PM activity that might be regressive and produce unplanned availability, if executed poorly. A hard-time rebuild is one that occurs based upon time, distance, or cycles. For example, if we have a policy to rebuild a machine based on it reaching a time/distance/cycles threshold, we may actually take a perfectly good operating asset out of service, disassemble it, then introduce failure modes in the process of putting back together.
To use a human-body analogy, consider that the risk of heart attack for Western males increases with age, particularly over the age of 50. How would you feel if, on your 50th birthday, your physician called and suggested that you make an appointment for a heart transplant? I would be very concerned. Among other things, I don’t know that my existing heart is defective. I can’t be sure that proposed transplanted heart transplant would be free of defects. And I am certain that anesthesia and the opening and closing of a body’s thoracic region carry risks.
♦ Wrong or Insufficient Inspections and Monitoring. To avoid the risks associated with hard-time maintenance, most organization employ inspections, condition monitoring, and non-destructive testing (NDT) to drive condition/inspection-directed maintenance. Doing so eliminates the guesswork from maintenance. When an abnormal condition is observed through inspections or monitoring, a notification is written and approved or denied. If approved, a priority is assigned, and the job is planned, scheduled, and executed to correct the problem or restore healthy conditions that, if not addressed, would increase the risk of failure. It’s imperative that we match the inspection and monitoring plan for an asset to its probable failure modes. It’s also crucial to inspect or monitor the assets health at the correct interval. If the interval is too long, a failure can transition from the incipient stage to the catastrophic stage between observations.
Referring again to our human body analogy, scheduling a heart transplant simply because one turns 50 years of age doesn’t make a lot of sense. But scheduling an electrocardiogram and a few other tests at the age of 50 does make sense. If heart disease is found, an appropriate course of treatment starts. It might be a pharmacological solution, angioplasty, by-pass surgery, valve replacement, or, possibly, a heart transplant. However, the decision would be based upon tests and data. (As I’ve written before, data are the difference between deciding and guessing.)
Better yet, turn the clock back to when you were 25. The risk of a heart attack is quite low for a healthy 25-yr-old. At that age, we could expect our physicians to check blood pressure, cholesterol, etc. A high cholesterol level doesn’t indicate a heart attack, nor does it guarantee that one would ever occur. But, given the fact that elevated cholesterol is a known root cause of heart disease, by taking actions to reduce it, one targets a primary root cause and helps reduce the likelihood of heart disease later in life.
CONCLUSION
To recap: Availability is an essential lagging metric for asset management. And it’s a primary driver of Overall Equipment Effectiveness (OEE). Unavailability can be planned or unplanned. The unplanned type of unavailability can be equipment-induced, production-induced, and/or marketing-induced. There are many causes for equipment-induced downtime.
This week, we’ve addressed incorrect equipment design, insufficient or excessive preventive maintenance, poorly executed preventive maintenance, and incorrect or insufficient inspection and monitoring. In next week’s article, week, we’ll focus on ineffective or inefficient work planning, poorly executed corrective maintenance, MRO supply chain quality, and MRO supply chain disruption, i.e., the other causes of unplanned, equipment-induced asset unavailability. Then we’ll turn our attention to production- and marketing-induced causes of unplanned unavailability.TRR
REFERENCES
Troyer, Drew (2008-2021). Plant Reliability in Dollars & $ense Training Course Book.
ABOUT THE AUTHOR
Drew Troyer has over 30 years of experience in the RAM arena. Currently a Principal with T.A. Cook Consultants, he was a Co-founder and former CEO of Noria Corporation. A trusted advisor to a global blue chip client base, this industry veteran has authored or co-authored more than 300 books, chapters, course books, articles, and technical papers and is popular keynote and technical speaker at conferences around the world. Drew is a Certified Reliability Engineer (CRE), Certified Maintenance & Reliability Professional (CMRP), holds B.S. and M.B.A. degrees. Drew, who also earned a Master’s degree in Environmental Sustainability from Harvard University, is very passionate about sustainable manufacturing. Contact him at 512-800-6031, or email dtroyer@theramreview.com.
Tags: reliability, availability, maintenance, RAM, metrics, key performance indicators, KPIs, OEE

