
Let’s re-cap previous parts of this series. When I initially addressed Overall Equipment Effectiveness (OEE), I challenged the conventional approach for describing the metric and even challenged the its name (see link below). I much prefer the term “Overall Business Effectiveness (OBE), because factors other than the equipment can affect Availability, Yield/Speed, and/or the Quality of the output from an asset or production process. In Parts 1 through 3 of this series on OEE’s Availability element, I addressed equipment-induced causes of unavailability (see links below). In this week’s article, we’re turning our attention to the production- and marketing-induced causes of unplanned asset or operational unavailability.
Click The Following Links To Previous OEE And Availability Articles
“Lagging Indicators For Asset Management: OEE (Sept. 5, 2021)
“OEE’s First Element: Availability, Part 1” (Sept. 13, 2021)
“OEE’s First Element: Availability, Part 2” (Sept. 27, 2021)
“OEE’s First Element: Availability, Part 3” (Oct. 3, 2021)
There are a number of production- and marketing-induced causes of unplanned asset or operational unavailability. They include: Operational Overload; Denied Access for Maintenance and Care; Incorrect Adjustment, Recipe or Set-up; Poor Changeover Efficiency or Effectiveness; and Supply-Chain Disruption – Material Unavailability (Fig. 1).
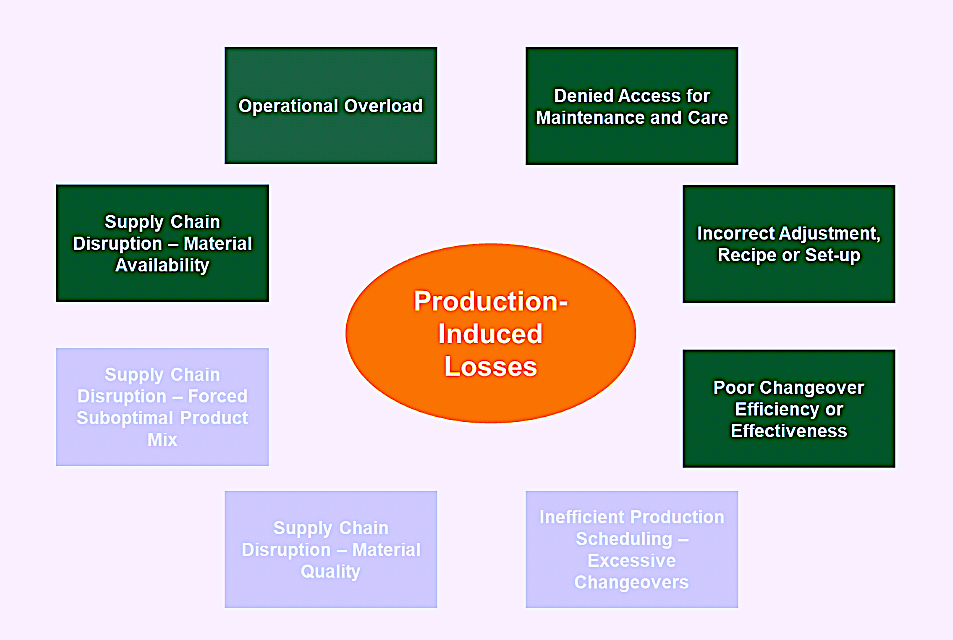
Fig. 1. The dark green boxes represent production- or operations-induced causes
for asset or operational unavailability.
It’s important to note that many production/operations-induced causes of unplanned unavailability can be byproducts of organizational misalignment. This type of misalignment occurs when different functional groups interpret the organization’s mission and vision in different ways because they view it through different perceptual lenses. A perceptual lens affects how people and groups sense and make sense of data and observations, which, in turn influences their actions. For example, the production/operations team view the mission and vision through the lens of revenue maximization. The supply chain team views it through the lens of cost minimization, and the maintenance team views it through the lens of asset reliability. The term “functional silos” is often used to refer to the difference. Therefore, communication is key to breaking down functional silos and minimizing inter-functional misalignment.
♦ Operational Overload. Arguably, the most notable cause for unplanned asset or operational unavailability occurs when machines are stressed beyond their design limits. Stress vs. Strength Interference is an important concept within the field of reliability engineering. Simply stated, it suggests that if the distribution of applied stress or strain on a part, component, or asset system is less than design strength, the asset will be reliable (Fig 2). Strength is determined by material selection, geometries, and the laws of physics and chemistry. It’s also influenced by the quality with which the machine was manufactured, installed, and commissioned.
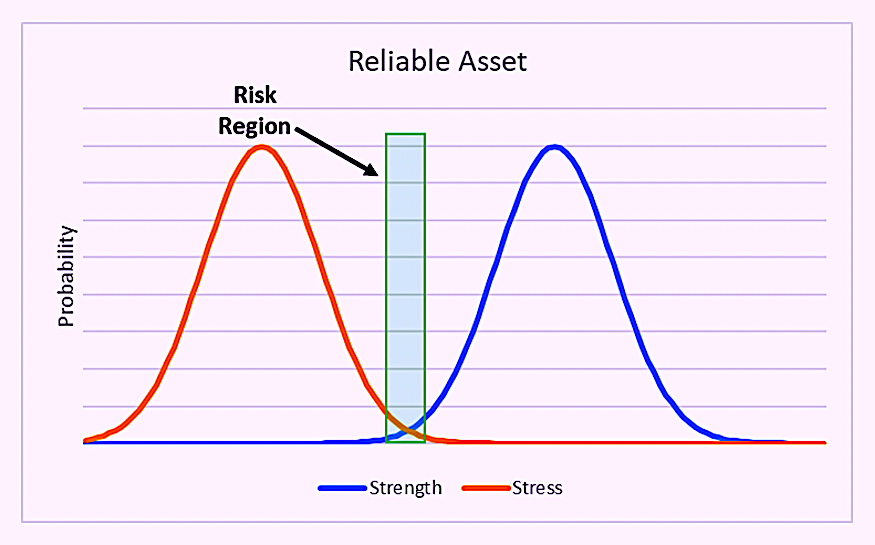
Fig. 2. Minimal interference between the tails of the strength
and stress distributions results in a reliable asset.
Production and operations teams are always focused on increasing production. Since production drives revenue, this makes a lot of sense. However, if assets are pushed beyond their limits, the balance between their strength and the applied forces is lost. This causes interference between the stress and strength distribution curves and increases the risk of failure (Fig. 3).
Overloading equipment is a common source of conflict between production and operations teams and their corresponding maintenance teams in manufacturing and process plants and other equipment- asset-dependent organizations. In many cases, turning the speed up to 12 on an asset that’s designed to run from 1 to 10 is counterproductive if the extra output results in unavailability and excess asset-care costs. Think of it this way: Would you prefer 100 hours of Availability at an output of 10/hour, or 80 hours of Availability at an output of 12/hour? The latter provides 960 units of production. But the former provides 1,000 units of production, and with less wear and tear on the machine.
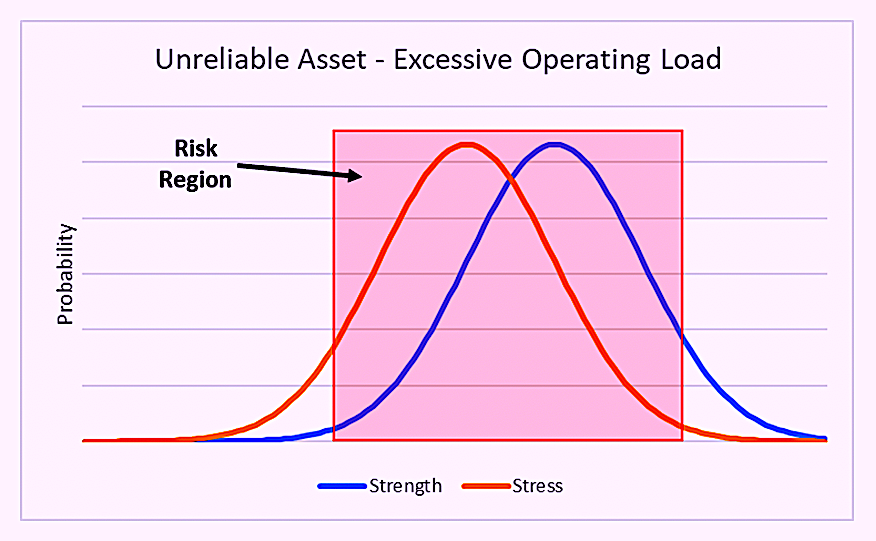
Fig. 3. Operating an asset beyond its design limits introduces
stress vs. strength interference that compromises reliability.
♦ Denied Access for Maintenance and Care. Another common cause for production- or operations-induced unavailability is denied access to perform asset maintenance and care. Again, production and operations teams are driven to maximize production. In some cases, this drive makes them apprehensive to release make the assets available for maintenance and care. If this occurs too frequently, it takes a toll on the integrity of the asset and, accordingly, compromises the asset’s strength. This leads to equipment failure and reduces asset availability (Fig 4). One could argue that this is an equipment-induced cause of unavailability, but the root cause is denied access to the asset to carry out maintenance.
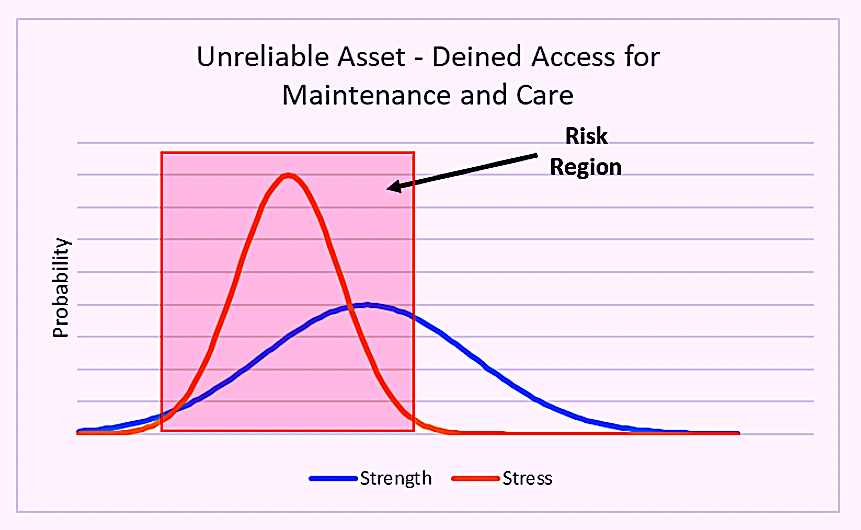
Fig. 4. Denied access to carry out asset maintenance and care
compromises the integrity and reliability of the assets.
♦ Incorrect Adjustment, Recipe, or Set-Up. General mis-operation by production/operations teams is another potential cause of unplanned unavailability. If equipment isn’t set up correctly (using the correct recipe), or if incorrect adjustments are made, it can induce a voluntary or involuntary machine trip that results in unavailability. This form of unavailability is typically due to the lack of or ineffective operating procedures and/or insufficient training of the operators. Increasing the operability of machines through use of intuitive markings and visual indicators can help reduce this unavailability.
♦ Poor Changeover Efficiency or Effectiveness. For many organizations, numerous products and/or grades of products are produced utilizing common assets. When it is necessary to carry out a changeover, the equipment will be unavailable from shutdown to restart. The effectiveness and efficiency with which the production/operations team completes the changeover can greatly affect production availability.
We generally plan for a certain amount of planned unavailability to complete the changeover. Of course, we try to minimize this time utilizing Single-Minute Exchange of Die (SMED) and Front-End Loading (FEL) principles discussed in the article on planned unavailability that we discussed in the first article in this series on Availability. Sometimes, though, things go wrong, and the result is unplanned unavailability.
SMED and FEL processes can be applied to a wide variety of production/operations-induced causes for asset unavailability. For example, while working on a pulp and paper project, we analyzed paper- break data. A paper break is where the paper being manufactured on a paper machine experiences a break and the operators must restart and stabilize the process. We found some operational teams taking over an hour to restore “A-quality” production and others averaging just 15 minutes. Using Success Root Cause Analysis (SRCA), which is like Failure Root Cause Analysis (FRCA), but focused on desirable practices, we analyzed and documented the practices of a 15-minute team, applied SMED principles, standardized the process and trained all teams. Average paper-break recovery times were substantially reduced.
♦ Supply-Chain Disruption — Material Unavailability. All production processes require material and energy inputs to function. If these supply chains are disrupted, a plant suffers availability losses. Sometimes, supply-chain disruptions are caused by phenomena beyond the control of the supply-chain team (natural disasters are a good example of this). In other cases, losses are cause by poor supply-chain management. For instance, unreliable suppliers are often selected based on low prices. But if this approach leads to disruptions and associated asset unavailability, the attractiveness of the bargain wanes quickly.
CONCLUSIONS
Bottom line: Overall Equipment Effectiveness (OEE) is an elegant, highly valuable metric for evaluating the performance of an asset. Availability, i.e., the number of hours an asset operates divided by the total available operational time (e.g., 8,760 hours per year) is a very important component of the OEE metric.
There are many causes for asset unavailability (some planned and some unplanned). Here, in Part 4 of our discussion on OEE’s Availability element, we’ve addressed production-induced causes for unplanned unavailability. Next week in Part 5,
we’ll address marketing-induced causes, then turn our attention to Yield/Speed and Quality, the other OEE elements.TRR
REFERENCES
Troyer, Drew (2008-2021). Plant Reliability in Dollars & $ense Training Course Book
ABOUT THE AUTHOR
Drew Troyer has over 30 years of experience in the RAM arena. Currently a Principal with T.A. Cook Consultants, he was a Co-founder and former CEO of Noria Corporation. A trusted advisor to a global blue chip client base, this industry veteran has authored or co-authored more than 300 books, chapters, course books, articles, and technical papers and is popular keynote and technical speaker at conferences around the world. A Certified Reliability Engineer (CRE) and a Certified Maintenance & Reliability Professional (CMRP), he holds B.S. and M.B.A. degrees. Drew, who also earned a Master’s degree in Environmental Sustainability from Harvard University, is very passionate about sustainable manufacturing. Contact him at 512-800-6031, or email dtroyer@theramreview.com.
Tags: reliability, availability, maintenance, RAM, metrics, key performance indicators, KPIs, OEE

