
In two recent editions of The RAM Review (see article links below), I discussed Mean Time Between/To Failure (MTBF/MTTF), which quantifies the average time between failure events. This week, my focus is on the Mean Time To Repair (MTTR) metric, which quantifies the average time required to recover from a failure event.
As it is with MTBF/MTTF, “average “can be a very dangerous number when examining MTTR data (see link to my article on that specific topic below). Like MTBF/MTTF, the MTTR to recover from a failure may be extremely variable and dependent upon both the failure mode and the level at which the failure is defined and evaluated, be it at the equipment unit, sub-unit, component/maintainable item, or part as defined by ISO 14224. In addition, it’s important to note that MTTR is significantly affected by an organization’s planning, scheduling, coordination, and execution of maintenance work.
Click The Following Links To Read The Previous Articles
“MTBF/MTTF (Mean Time Between/To Failure, Part 1” (Aug. 15, 2021)
“MTBF/MTTF (Mean Time Between/To Failure, Part 2” (Aug. 23, 2021)
“As A Metric, ‘Average’ Can Be A Dangerous Number” (May 15, 2021)
REACTIVE OR CONDITION-BASED MAINTENANCE?
Reactive maintenance jobs are MTTR killers. When a machine fails without warning, the organization may not be well positioned to execute needed repairs in a timely fashion. This is especially true if the job requires one or more of the following:
-
- erection of scaffolding or completing pre-work preparation
- expediting parts or materials (particularly those with long lead times)
- machining or fabricating parts
- building or repairing the foundation or other civil/structural elements
- procuring special tools or equipment, e.g., a large capacity crane, to complete the job
- hiring specialized or possibly scarce available labor.
In a reactive scenario, where the machine fails without warning, all of those activities must be competed while the machine is down and production is slowed or halted (Fig. 1). In that scenario, all aspects of the planning, preparation, and execution of work are “internal” activities, meaning they’re completed while the machine is down and not producing.
Making matters worse, reactive jobs often experience a great deal of collateral or secondary damage, which increases the scope of the job to prepare for and executive corrective maintenance actions. Larger jobs are more costly and generally take more time, which further drives up the MTTR and the variability about the mean. Compounding the problem is the fact that in reactive situations we’re often required to “make do” with sub-optimal parts, which will work in a pinch but aren’t ideal. This can adversely affect reliability in both the short term and the long term.
In the short term, using sub-optimal parts or materials sets the stage for another failure. In the long term, if the organization lacks accurate bills of materials (BOMs) and is a like-for-like “parts changer,” the next time the failure occurs, the previously improvised incorrect sub-optimal parts become the standard. And it’s likely that they’ll be changed out with the same sub-optimal parts the next time that the same failure occurs. This theme can repeat many times before a root-cause analysis (RCA) event is scheduled to get to the bottom of the mysterious and new repeat-failure problem. These vicious cycles can repeat several times before the root cause is corrected. In truly desperate situations, we also may be forced to raid the “junk yard” of failed components to scavenge parts.
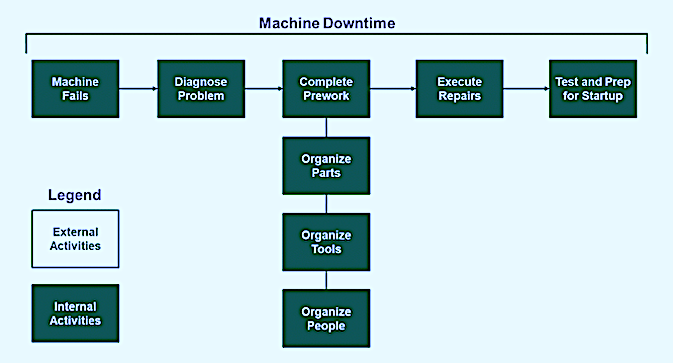
Fig. 1. In a reactive maintenance job, all tasks required to prepare for and execute corrective
actions must be completed while the machine is offline.
The advance warning of failure that’s provided by inspection rounds, condition monitoring such as vibration analysis, oil analysis, ultrasonic analysis, infrared thermographic analysis, motor analysis, etc., and nondestructive testing (NDT) can greatly reduce the Time To Repair (TTR) for a maintenance job. It enables planners to separate internal activities, i.e., those that can only be completed while the machine is stopped, from “external” activities that can be completed as preparatory work while the machine is running. This approach can considerably reduce MTTR and the associated adverse impact on production time (Fig. 2). It also decreases variability about the MTTR for standardized repair jobs in response to commonly observed failure modes.
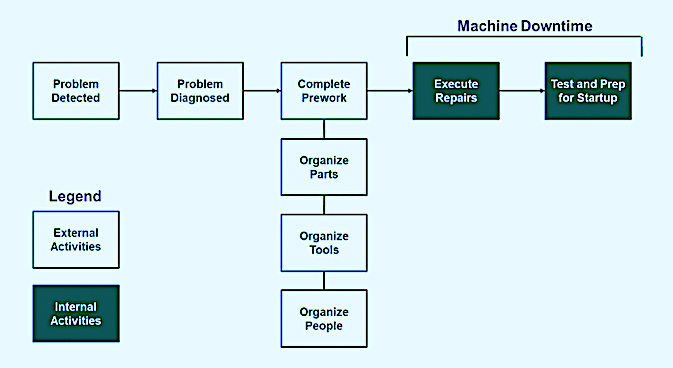
Fig. 2. Advance warning enables advance planning and reduces machine downtime and MTTR.
TRACK MTTR BY MAINTENANCE ACTIVITY
In addition to tracking MTTR at appropriate levels in the ISO 14224 hierarchy and by different failure modes, it makes sense to track machine downtime by maintenance activity. For example, while the machine was shut down, how much time was spent completing pre-work? How much time was spent finding parts? How much time was spent finding tools? How much time was spent finding people? How much time was spent awaiting permits?
Tracking performance at the maintenance-activity level can reveal deficiencies and opportunities to improve planning, preparation, materials management, and other aspects of the corrective-maintenance process. While it’s ideal to detect impending failures in advance of their occurrence and plan and schedule accordingly, and we must strive to predict these events to the extent that we can, doing so is not always possible. Unplanned events will occur, so we must expect and be prepared for the unexpected and attempt to prepare as proactively as possible with standard parts kits and standardized corrective work plans to address reactive, unplanned events as effectively as possible.
CAN REPAIR TIME BE TOO LOW?
We generally think of MTTR as a metric that we want to minimize. For the most part, that’s true. However, the active maintenance time where we’re executing repairs, testing, and prepping for startup can be an exception.
In a reactive maintenance scenario, when the team is under the gun to get the machine back up, running, and producing, there is often a great deal of pressure to hurry the maintenance process. This can lead to short-cuts, particularly in the area of precision maintenance. If, among other things, we circumvent precision fastening practices (for threaded fasteners, welds, etc.), alignment of shafts, alignment of pulleys and sheaves and tensioning of bolts, precision balancing of rotating assemblies, proper lubrication, and contamination control, we’re setting the stage for the next failure. Likewise, if we fail to properly test prior to putting a machine back online, we’re setting the stage for the next failure.
Your best strategy for driving down TTR is to convert internal work that can only be completed while the machine is down to external work that can be completed while the machine is running. Shortcuts that compromise maintenance quality rarely pay off. Moreover, in some cases, hurry-up pressure can produce safety shortcuts, which is never a good thing.
CONCLUSIONS
Mean Time To Repair (MTTR) is an important metric for measuring an organization’s preparedness to complete maintenance work. It also reveals the organization’s effectiveness at inspecting equipment to uncover potential failures with enough time to complete necessary preparatory work that’s required to limit downtime to active repair time and testing in preparation for restarting and getting a machine back online.
Like any average, though, MTTR can be a misleading number. It’s important to analyze MTTR at the proper asset hierarchy level and on a failure-mode by failure-mode basis. It’s also helpful to evaluate the time required to execute various aspect of the maintenance problem from diagnosis to testing and prep for restart to find opportunities to improve efficiencies.
Next week, I’ll dive into the very complex and multidimensional subject of Overall Equipment Effectiveness (OEE).TRR
REFERENCES
ISO 14224:2016. Petroleum, petrochemical and natural gas industries – Collection and exchange of reliability and maintenance data for equipment. International Organization for Standardization. Geneva, Switzerland.
ABOUT THE AUTHOR
Drew Troyer has over 30 years of experience in the RAM arena. Currently a Principal with T.A. Cook Consultants, he was a Co-founder and former CEO of Noria Corporation. A trusted advisor to a global blue chip client base, this industry veteran has authored or co-authored more than 300 books, chapters, course books, articles, and technical papers and is popular keynote and technical speaker at conferences around the world. Drew is a Certified Reliability Engineer (CRE), Certified Maintenance & Reliability Professional (CMRP), holds B.S. and M.B.A. degrees. Drew, who also earned a Master’s degree in Environmental Sustainability from Harvard University, is very passionate about sustainable manufacturing. Contact him at 512-800-6031, or email dtroyer@theramreview.com.
Tags: reliability, availability, maintenance, RAM, metrics, key performance indicators, KPIs, MTTR, ISO 14224

