
In my last article for The RAM Review (May 8, 2021), I focused on the important role metrics play in driving behaviors in a plant (see link below) I want to carry on with that theme this week to discuss mean time between failure (MTBF), mean time to failure (MTTF), and mean time to repair (MTTR). These are important lagging metrics that are widely employed by reliability engineers and other asset management professionals. They are important because they heavily impact overall equipment effectiveness (OEE), earnings before interest, tax, depreciation, and amortization (EBITDA) and return on net assets or return on capital employed (RONA/ROCE).
Note, however, that while MTBF/MTTF and MTTR are useful for trending purposes, if not well understood, they can be dangerously misleading. This is particularly true when making decisions to rebuild or replace equipment or components based upon time. Let’s explore MTBF and MTTF in more detail. I’ll address MTTR in a future issue of The RAM Review.
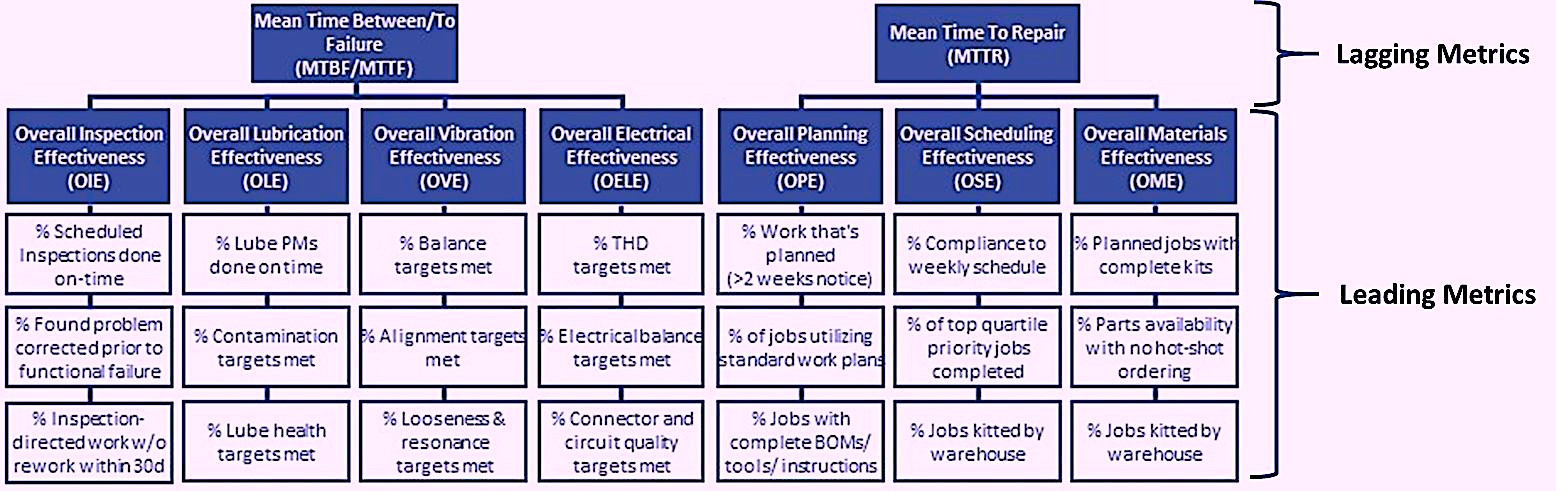
Fig. 1. MTBF, MTTF, and MTTR are lagging metrics that drive OEE
and higher-order corporate performance metrics.
MTBF/MTTF AND RELIABILITY GROWTH
Although it is often tricky to employ MTBF or MTTF to determine when to rebuild or replace equipment, these metrics are exceptional for tracking reliability growth or decline. And, after all, our goal is to increase the reliability of our equipment by employing various proactive asset- management strategies.
In the early stages of an initiative, we often observe a low MTBF or MTTF and a very large amount of deviation, as is depicted by the red curve in Fig. 2. As the organization’s reliability practices improve, we see an increase in the MTBF or MTTF, and the distribution begins to tighten as we start to address the forcing functions that lead to failure and improve our monitoring practices. This is illustrated by the burnt orange curve in Fig. 2.
As we begin to approach industry best practice for managing the reliability of an asset, the MTBF or MTTF further increases, and the distribution tightens up even more because the standard deviation is shrinking, as illustrated by the green curve in Fig. 2. The reason why the standard deviation increases is because in dealing with the controllable forcing functions that lead to failure, we’re left with a single or very small number of dominant failure modes that represent the design limitation. At this stage, further reliability improvement would necessitate a change in equipment design, which may or may not be cost justifiable.
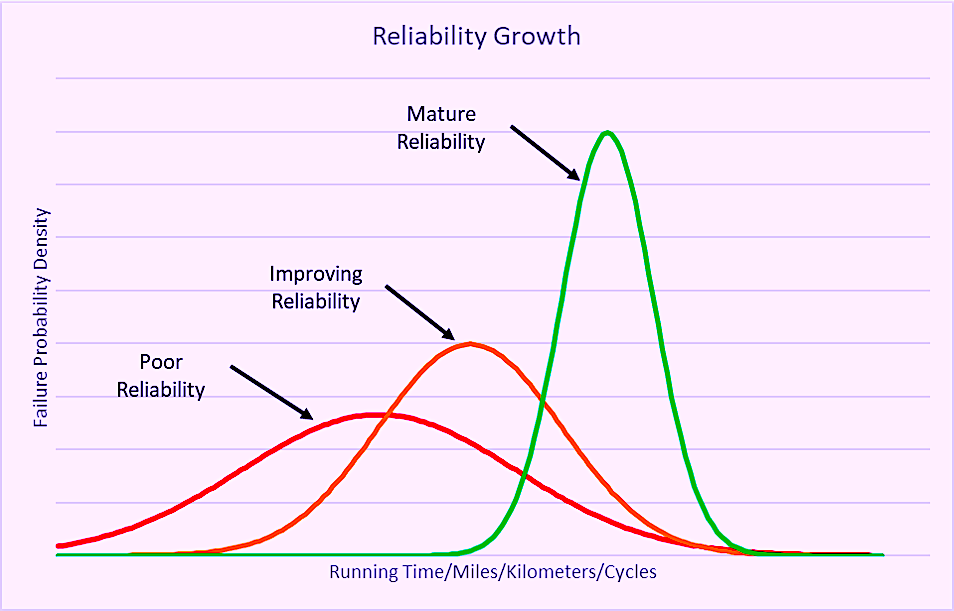
Fig. 2. Trending MTBF or MTTF over time provides a great indication about the
effectiveness of our efforts to improve and grow reliability.
MEAN: A MEASURE OF CENTRAL TENDENCY
MTBF and MTTF represent the average of several observations. In measurement, the arithmetic average value, or mean, is referred to as a measure of central tendency. Median is another measure of central tendency. Median is the middle value of a data set that has been ordered from smallest value to largest value. In general terms, a measure of central tendency has limited value without a measure of variability around that data set. This is typically calculated as the standard deviation. Assuming a Gaussian distribution, which produces the familiar symmetrical bell-curve shape, there is a 95% probability that a value will fall within +/- 1.96 standard deviations of the average. In reliability engineering, we’re not concerned about the machines that outlast the average, so there’s a 95% probability that we’re acting in time if we subtract 1.645 standard deviations from the average.
For example, suppose we have good data on the time to failure (TTF) for a machine, and we want to employ time-based maintenance. To keep the math simple, let’s assume a Gaussian distribution with a MTTF of 1,000 hours and a standard deviation of 20 hours. We can subtract 1.645 X 20 from 1,000 and define the point in time at which we should take action. In this case it would be 1,000 – (1.68 X 20) = 967 hours. Sounds relatively simple, right? Hold my beer…IT’S NOT THAT SIMPLE
NASA’s Reliability-Centered Maintenance (RCM) Guide for Facilities and Collateral Equipment (2008) reveals the results of a study during which 30 identical 6309 deep-groove ball bearings were run to failure under controlled conditions on a test stand. The data are illustrated in a bar chart in Fig. 2. The arithmetic average (MTTF), which is identified by the dashed line, is about 93 million revolutions. But, as is visually apparent from the scatter of the data, the standard deviation is about 70 million revolutions. Bear in mind that this is the degree of variation observed under highly controlled test-stand conditions. The variability of forcing functions associated with true in-service bearing applications would serve only to increase the variability.
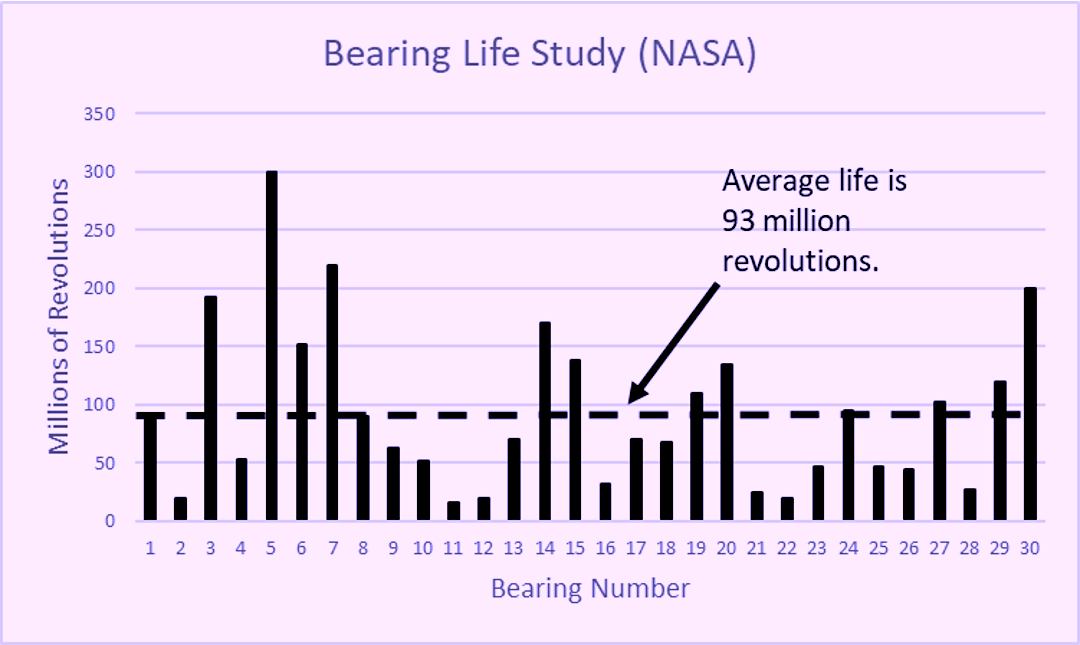
Fig. 3. Results of a ball bearing life test from the NASA RCM Guide.
If we simply scheduled a bearing changeout at the 93-million revolution average, more than 50% of the units would have failed prior to the scheduled changeout point. What would happen if we decided to use the bearing failure data to determine a good time to change out the bearings to avoid an unplanned failure? If we assumed a normal distribution (the bell curve), and we want to be 95% sure of replacing the bearing before a failure, would need to subtract 1.645 standard deviations from the average (MTTF) to determine the correct change out time. So, 93 – (1.645 X 70) = -22 million revolutions (Fig 3). That means we would have to change the bearing before even starting the machine following the previous changeout!
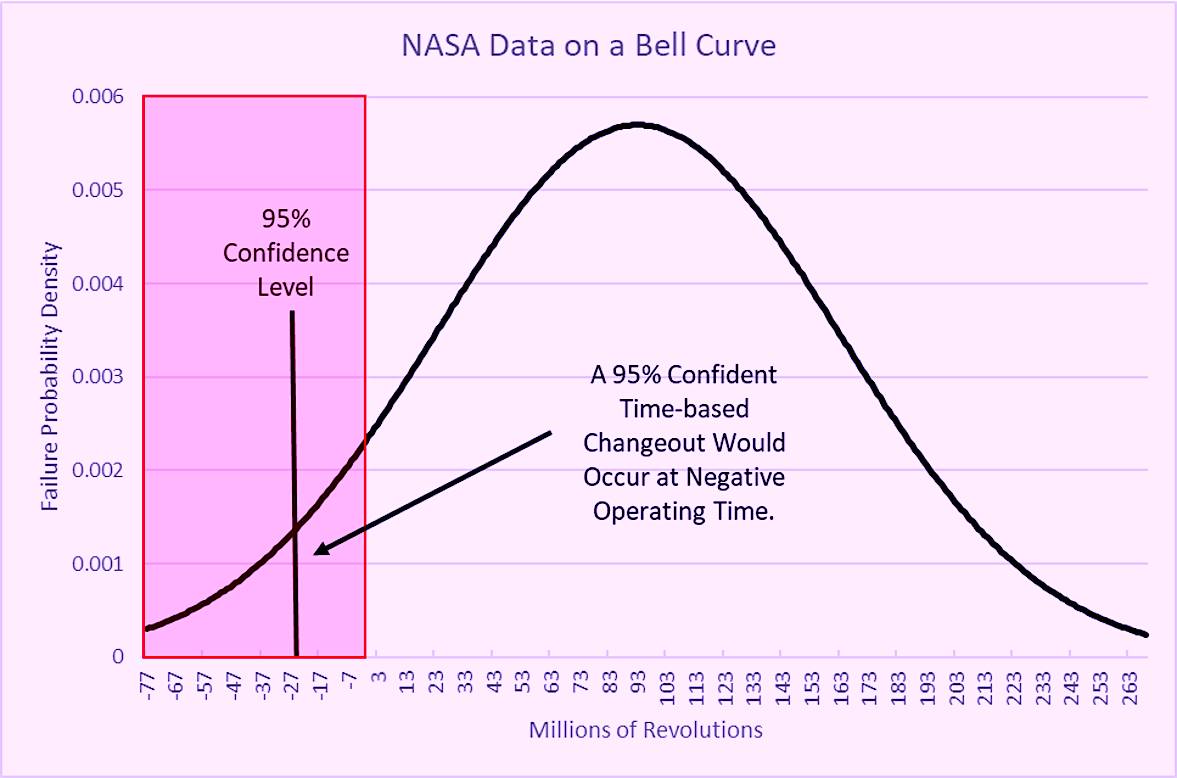
before we started using it, if we want to be 95% confident.
THE BELL CURVE DOESN’T ALWAYS WORK
It should be apparent that maintenance can’t be done on negative operating time. And, obviously, it would be impossible for the bearings in our example to run for a negative amount of time. This brings me to my point: The bell curve that’s associated with the normal (Gaussian) distribution isn’t universally applicable. The tell-tale sign of a data set not being normally distributed is that the average (or mean) and the median aren’t equal. For the NASA bearing data, the average is 93 million revolutions, but the median is 68 million revolutions. This is indicative of a few bearings enjoying a very long life, which skewed the average.
In statistics, we discuss observations in terms of “moments” of the distribution. The average, or expected value, is the first moment. The variance, from which the standard deviation is calculated, is the second moment. These are the measures with which people are most familiar. However, there are two other moments of the distribution: skewness and kurtosis.
Skewness, the third moment of the distribution, describes whether the distribution is uniform (bell curve) or if it leans to one side or another. If the skew value lies between -0.5 and 0.5, the distribution is relatively symmetrical. If the skewness lies between 0.5 and 1.0 or -0.5 and -1.0, the distribution is moderately skewed. If the skewness value is greater than 1.0 or less than – 1.0, the distribution is severely skewed. If the skewness is a positive number, the distribution is skewed right and if the skewness number is negative, the distribution is skewed to the left. Kurtosis, the fourth moment of the distribution represents the sharpness of the peak of the distribution.
The skewness for the bearing data from the NASA RCM Guide is 1.19, indicating that the data are extremely skewed to the right. Utilizing a software called @Risk, developed by Palisade, we evaluated the NASA bearing data to determine the best-fit distribution. It turns out that for the bearing data, the lognormal distribution is the best fit (red curve in Fig. 4). By converting the data to the lognormal distribution, we see that we’d need to change the bearing out at 15 million revolutions to be 95% confident of avoiding an unplanned failure. This is more palatable than the changeout at an impossible negative 22 million revolutions that we calculated in the normal distribution scenario. But changing at 15 million revolutions represents only 16.1% of the 93- million-revolution MTTF. Changing out at such a high frequency is costly in terms of parts, labor and lost production. For this type of application, we would typically recommend a condition-directed changeout, based upon vibration analysis or some other condition monitoring directed scheduling, rather than time/miles/kilometer/cycles-based-maintenance scheduling.
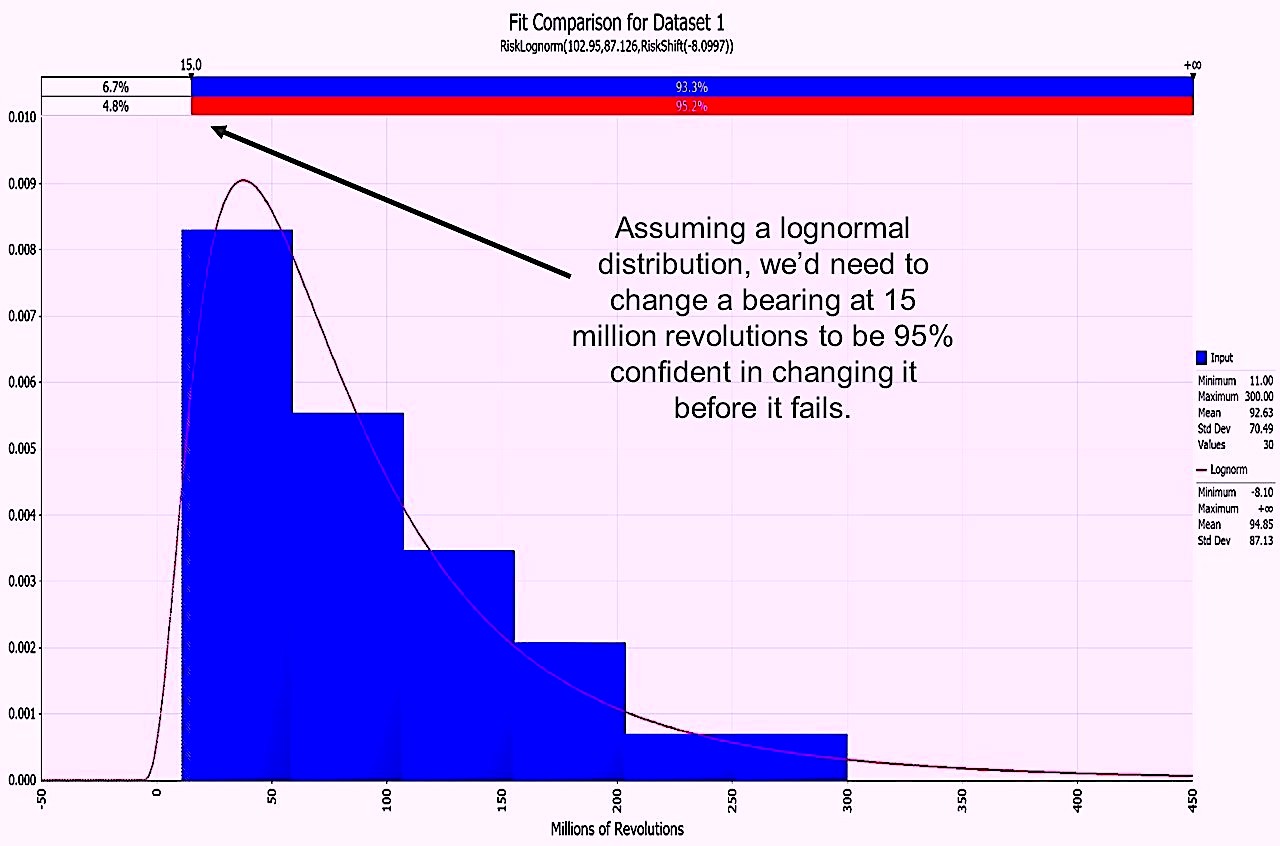
Fig. 5. The lognormal distribution was found to best represent the NASA bearing data.
CLOSING WORDS
As we’ve illustrated, average is a very complicated number. Average, or mean, as a measure of central tendency without an understanding of the variation, skewness, and kurtosis around that point can lead to poor, ill-advised decisions. Approach average values with caution. And it’s always advisable to conduct analysis of the distribution before making decisions based upon a data set. Tracking MTBF and MTTF over time, though, is a great indicator of reliability growth and proof that our efforts to address and manage the root causes of machine failure are working.
Next week, we’ll continue our journey through the world of metrics by focusing on Overall Inspection Effectiveness (OIE). It’s a leading metric that serves to drive proactive behaviors.TRR
ACKNOWLEDGEMENT
Many thanks to my T.A. Cook colleague Tong Zou, PhD, for his generous support on the use of the @Risk software to conduct the distribution analysis of the NASA bearing failure data and for his technical review of this article.
REFERENCES
NASA (2008). Reliability-Centered Maintenance (RCM) Guide for Facilities and Collateral Equipment (https://www.nasa.gov/sites/default/files/atoms/files/nasa_rcmguide.pdf). Accessed 14 May 2021.
@Risk Software, by Palisade (https://www.palisade.com/).
ABOUT THE AUTHOR
Drew Troyer has over 30 years of experience in the RAM arena. Currently a Principal with T.A. Cook Consultants, he was a Co-founder and former CEO of Noria Corporation. A trusted advisor to a global blue chip client base, this industry veteran has authored or co-authored more than 250 books, chapters, course books, articles, and technical papers and is popular keynote and technical speaker at conferences around the world. Drew is a Certified Reliability Engineer (CRE), Certified Maintenance & Reliability Professional (CMRP), holds B.S. and M.B.A. degrees, and is Master’s degree candidate in Environmental Sustainability at Harvard University. Contact him directly at 512-800-6031 or dtroyer@theramreview.com.
Tags: reliability, availability, maintenance, RAM, metrics, key performance indicators, KPIs, workforce issues

