
If you’re a manager or engineer at a manufacturing or process-industry plant, you probably don’t get through a day without learning of some type of equipment failure or an asset that needs corrective action. While you may not know exactly what maintenance will be required, or where or when, you’re unlikely to encounter a completely new and unique problem.
Unfortunately, most organizations fail to leverage the repeatable nature of maintenance work by creating standardized work plans. To take advantage of this opportunity, we must set ourselves up for success by standardizing the notification process, using a standard taxonomy of failure modes and mechanisms, and by standardizing the assignment of standardized work plans.
This article explains how to execute the standardization of maintenance-work management, and highlights the associated benefits, including improved wrench-time performance, reduced costs, improved work quality, improved safety, and enhanced reliability analytics.
STANDARIDIZATION STARTS WITH NOTIFICATIONS
The impetus for creating a notification or work request may come from a number of sources, including, among others, the control room, operator rounds, technician rounds, and condition monitoring (Fig. 1). Unfortunately, these notifications are typically written in free text. Moreover, using free text, five different people will likely describe the same event in five different ways. This creates a number of problems.
First, the gatekeepers, i.e., those who vet notifications, determine what’s in and what’s out, and assign a priority to approved jobs, may struggle with vaguely worded notifications. Reliability engineers also may struggle to analyze free-text notifications. These engineers need to group failures by type to statistically analyze their different modes and mechanisms. Free text notifications make this rather difficult.
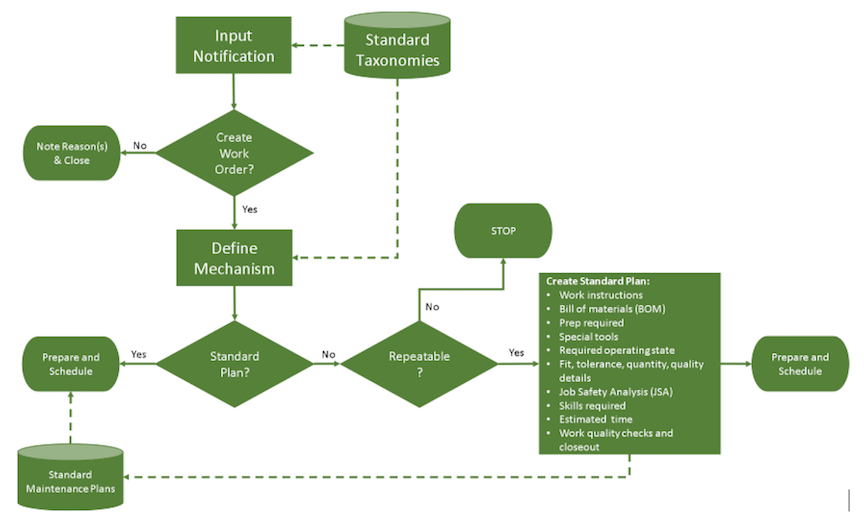 Fig. 1. A standardized work-management
Fig. 1. A standardized work-management
process-flow diagram.
Fortunately, there’s an easy fix for free-text dilemma. IEC 60812 and ISO 14224 both offer standardized taxonomies for failure modes, which is what is reported in a notification.
The failure mode reflects what is observed and is typically expressed in a relatively simple statement that can be selected from a dropdown list. It’s great to have the person making the notification embellish with text description, but we need to standardize the classification of the input.
Figure 2 offers a simple example derived from IEC 60812 of observable failure modes for a centrifugal pump. If this job were approved by a gatekeeper, it would move to the next stage. If not, it would be appropriate to note the reason why the notification was discarded.

Fig. 2. Standard taxonomy of failure modes for a centrifugal pump
that was derived from IEC 60812.
From there, we need to describe the observation to define the failure mechanism. This too can be easily standardized.
Figure 3 illustrates how a simple standardized taxonomy of failure mechanisms can be created. If an external leak is observed for a centrifugal pump, it’s either going to be process fluid or lubrication. Accordingly, the observer would check the process fluid and then select from a manageable list of descriptors, to include mechanical seal, packing, inlet flange, inlet piping, outlet flange or outlet piping, checking all that apply.
Again, the observer is free to embellish with text descriptions, but classifying notifications using a standard taxonomy of failure modes and mechanisms helps to clarify the problem and creates a powerful database for reliability engineers to analyze.
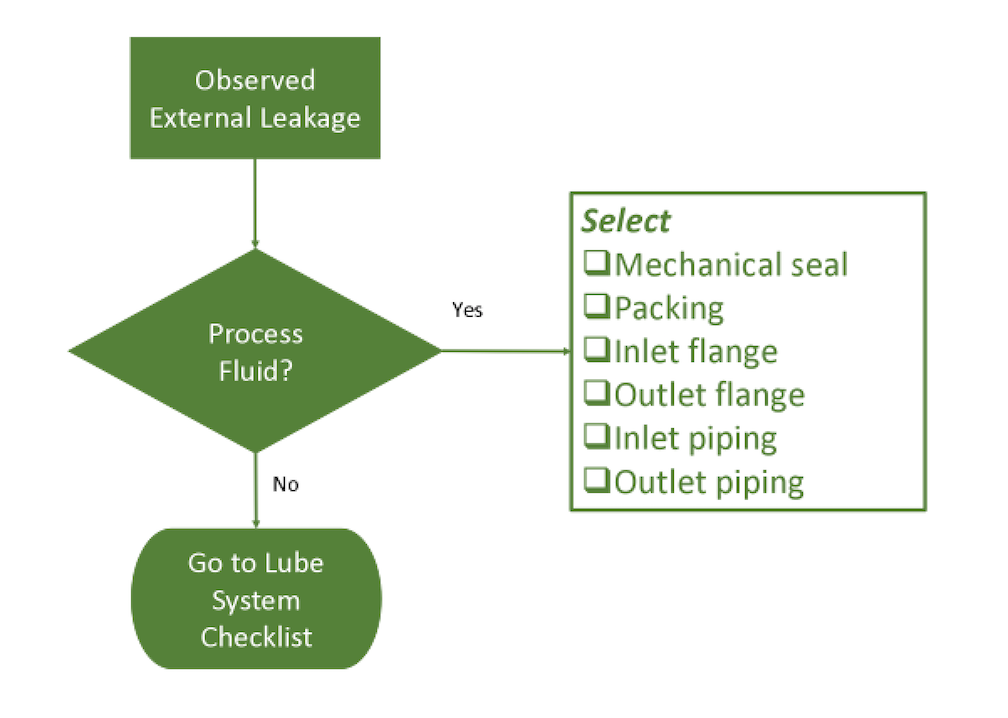
Fig. 3. Simple description of an external process-fluid leak
for a centrifugal pump.
From here, the standardizations continue to the assignment of urgency. The most urgent job is, of course, a functional failure that creates a health, safety or environmental (HSE) risk, has taken the entire plant down, significantly reduced production yield, is adversely affecting quality or prohibits the plant from making its most profitable mix of products. In these situations, the machines are deciding what service they want and when a critical job is created as a byproduct. After that are the failures that are imminent this month. These are sometimes called P1 or Priority 1 events. Those jobs all get the highest priority, second only to critical jobs.
For other jobs that are more proactive or predictive in nature, we need to assign a job-priority number (JPN) based upon a standardized process. There are many approaches to this process. We prefer a quantitative approach. Figure 4 illustrates one such approach, which is simple and easy to use. It utilizes a 1 to 5 scoring system on two factors: condition severity and functional severity.
The condition-severity score indicates how bad things are. For example, a score of 1 indicates that a functional failure is not likely. Conversely, a score of 5 indicates that a functional failure is imminent this month.
The functional-severity score indicates how bad the effects will be in the event that the system is allowed to fail. A score of 1 indicates that the failure is non-critical to operations. A score of 5 indicates a failure is critical to operations and will shut the entire plant down.
This simple system yields a score of 1 to 25. It’s possible to add another 1-to-5-scored category representing the time domain to define how long operations will be affected, which would yield a new JPN range of 1 to 125.
Conversely, one can simply multiply the two-factor JPN by the number of lost production hours. In either case, you’ll want to trend your average JPN over time. The desired movement of the JPN KPI is downward, which is indicative that you’re doing more and better proactive maintenance work.
Using the example of the notification for a pump that has an external leak, if the unit is leaking a hazardous or flammable material, it may well be classified as HSE critical. However, if it’s a slow water leak and there is a standby pump, it would fall into the non-critical and non-P1 category and receive a comparatively low priority number. We can’t over-emphasize the importance of a downward-trending average JPN. It would mean we’re able to take proactive action and repair little problems before they grow into big ones.
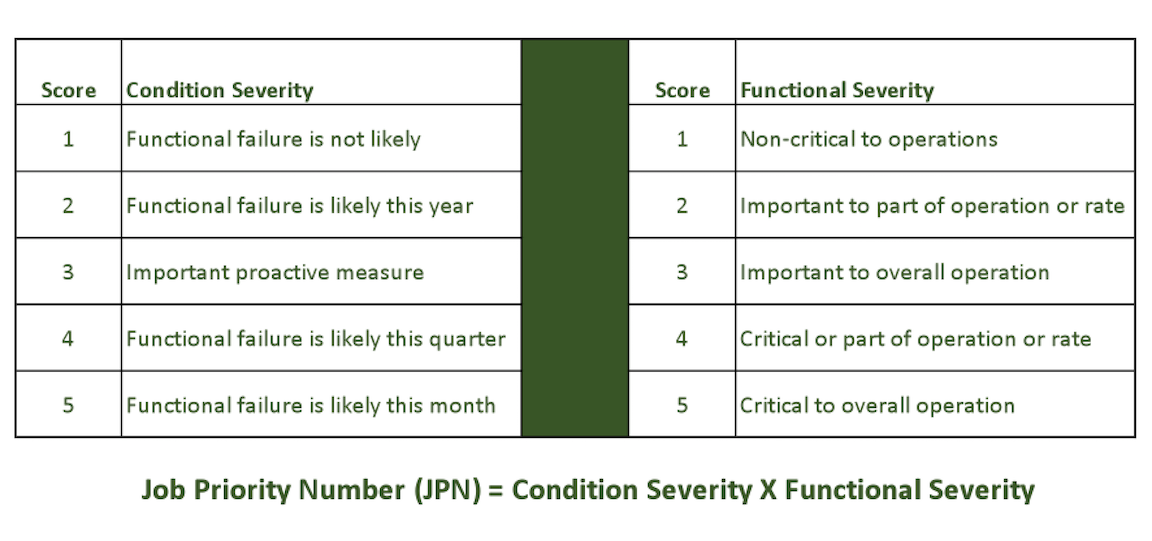
Fig. 4. Multiply the condition-severity score by the functional-severity score
to calculate the job priority number.
STANDARDIZING WORK PLANS
Once a job has been identified, approved, and prioritized, it moves on to the planning process. There are very few new failures in a typical plant. We see the same ones again and again. However, plants tend to plan jobs as though they are new and unique. This fails to leverage the repeatable nature of maintenance work to your advantage.
Referring back to Fig. 1, if a standardized plan exists for the requested job, then the planner simply selects that plan, makes any necessary modifications and ensures that everything is in place to designate the job ready to schedule, including assuring that parts are in stock and pre-kitted.
If no standard plan exists for a particular work order, then the planner creates one utilizing a predefined organizational standard. A standardized job plan should include work instructions, bill of materials (BOM), prep required, special tools, required operating state, fit, tolerance, quantity, quality details, Job Safety Analysis (JSA), skills required, estimated time, work quality checks, and closeout requirements,
As much as possible, standard jobs should be created from standardized components and/or part level plans. For example, it’s unnecessarily confusing for workers if the maintenance plan to fix or PM a motor on an air handling unit is different from the plan to fix or PM the motor on a pump, particularly if they are identical motors.
Additionally, standardized task-level language helps to avoid unnecessary confusion. By that, we mean if two jobs each require 10 discreet tasks to complete the job and three of the tasks are identical, those tasks should be written the same way, and only changing or modifying what absolutely must be changed. Keeping it simple makes it easier for craftspeople to get in a rhythm and learn by repetition. It also makes training and craft supervision much easier and more predictable.
For jobs that are performed routinely, we like to see parts pre-kitted in batches, assigned their own stock keeping unit (SKU) code and stored ready to pull. This saves a lot of time and reduces the likelihood of a common job not being completed due to a stock-out situation.
Carry standardization to the scheduling process as well. The JPN score is a critical element in determining the weekly scheduling, drawing from a pool of planned jobs that are ready to schedule. We like to see 125% of the week’s available labor hours scheduled, assuming a world-class wrench-time of about 55%.
Let’s say that you have a crew of 50 next week, and each person is scheduled to work 40 hours. You have 2,000 man-hours. Assuming a 55% wrench-time, you have 1,100 wrench-time hours available. You want to schedule enough jobs, with priorities assigned to each, to account for 1,375 man-hours. The reason for doing so is simple: During the maintenance week, it’s not uncommon for scheduled jobs to be deferred for various reasons. You want to have enough jobs teed-up, parts kitted, and in your supervisors’ hands, along with JPN scores, in the event that the schedule moves. That way, supervisors can adapt effectively to changes.
BOTTOM LINE
If there are standard processes for entering notification or works requests, and a standard job plan is in place for the requested work, the planning process becomes very simple. Organizations that do an excellent job in creating and maintaining standardized job plans typically have a planner-to-craft ratio in the range of 25 or 30 to 1. This type of ratio is indicative of a very efficient planning organization. Operations that don’t standardize their job-planning processes have a much lower planner- to-craft ratio.
Job-plan standardization also improves worker productivity (wrench-time) and increases work quality. Thus, it is clearly a critical element in your pursuit of world-class maintenance-work management.TRR
ABOUT THE AUTHORS
Drew Troyer, CRE, CMRP, Editor, and Lance Bisinger, CMRP, CRL, are Principals with T.A. Cook Consultants, The Woodlands, TX. For more information about the company, visit us.tacook.com.

