
The ultimate goal of the maintenance work management process is to ensure that the highest priorty jobs are executed effectively and on time to prevent functional failure of plant equipment. Achieving this goal requires that each of the serially connected sub-processes is done correctly. The process to approve notifications submitted by operators, maintenance technicians, condition monitoring technicians, etc., is crtical. This is frequenty called “gatekeeping” because the approver determines what notifications enter the work planning, scheduling, and execution stages of the process, and which ones are ignored. Whether the work is routine maintenance or shutdown/turnaround/outage (STO)-related, effective gatekeeping is essential to success.
THE INSPECT-TO-EXECUTE PROCESS
The individual steps in the serial-work-management process include: 1) inspection; 2) work notification; 3) work notification approval; 4) work request generation and priority assignment; 5) work planning; 6) work scheduling; 7) work execution; 8) work quality check; and 9) work closeout. As previously stated, step 7, work execution, is the ultimate goal for the process. However, as a serial process, to reach step 7, steps 1 through 6 must be successfully executed. Gatekeeping is a critical decision point in that process.
The work-approval or gatekeeping process is closely linked to the work-notification process. Many maintenance organizations execute the notification process poorly, which sets the stage for a failed gatekeeping process. Too often, the notification process is casual and lacks structure. It’s rare that we experience a truly unique problem in the plant. In fact, we typically see the same problems occurring again and again. The repeatible nature of maintenace work lends itself to standardization, including in the notifcation process.
For most systems, sub-systems, and components in the plant, we can fairly easily standardize notifications based upon commonly observed failure modes and create a taxonomy of notifications to replace more casual methods. Doing so demystifies the notificatons for supervisors, reduces time wasted searching for supporting data, and lowers the likelihood of gatekeeping misteps. This goes a long way to ensuring that we request, priortize, plan, schedule and execute the maintenance work that’s most important for assuring the reliability of the plant.
GATEKEEPING FALSE POSITIVES & FALSE NEGATIVES
In measurement theory, a false positive, or Type I error, occurs when one accepts a hypothesis (rejecting the null), but the the hypothesis is actually false. These errors occur as a result of poor experiemental design or statisitial abnormalities. False negatives, or Type II errors, occur when the researcher rejects the hypothesis (accepting the null hypothesis) when the hypotheisis is actually true.
A little closer to home, we’re hearing a lot about false negatives with respect to testing for the COVID-19 virus. For COVID-19, a false positive occurs when the test says that an individual has been infected, but reality they have not. In COVID-19 testing, a false positive becomes a nuisance and an inconvenience. A COVID-19 false negative, on the other hand, where the test says an individual is not infected when, in fact, he or she is, can be a very dangerous situation. That’s because a person who receives a false negative may not take the necessary precuations to self-quarantine, and, thus, can exacerbate the spread of the virus.
We can apply a similar logic to the maintenance-work-management gatekeeping process. When a maintenance technican, operator, manager, or engineer writes up a maintenance notification, it’s often that person’s hypotheisis about what’s happening, what’s causing it, and how risky it is. If the gatekeeper approves a work notification that is not accurate and not valid, the result is a false positive. We convert the notification to a work request that goes into the planning, scheduling, and execution process (Fig. 1). False positives in the gatekeeping process result in wasted resources and, in some cases, failure to compete work that truly is important.
False negatives in the maitnenance-gatekeeping process occur when a notification is valid, i.e., the work is required, but the gatekeeper rejects the notification and no work request is issued (Fig. 1). False-negative gatekeeping decisions can carry significant consequences. Failure to complete necessary maintenance work can lead to functional failure that affects production, collateral damage that increases the scope of a reactive repair job, and, in some instances, introduces safety and/or environmental risks.
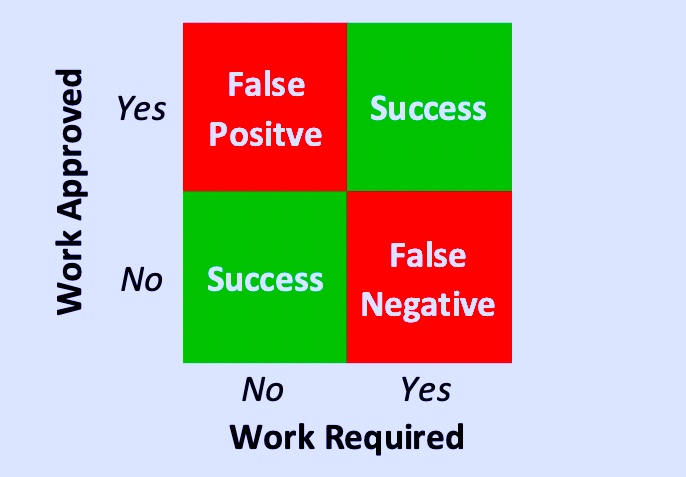
Fig. 1. False positives and false negatives in the maintenance-gatekeeping process.
HACKS TO GET GATEKEEPING RIGHT
False positive and negative outcomes in the maintenance gatekeeping process occur because: a) the person writing the notification fails to provide a sufficient amount of clear and accurate information; b) the gatekeeper fails to obtain the necessary supplementary information required to make a correct decision; c) the gatekeeper applies a flawed decision-making process to gatekeeping decisions, or; d) some combination of the above.
Because gatekeeping is so essential to the maintenance-inspect-to-work-management process, we must minimize false positives and false negatives. Here are some easy hacks to help you improve your gatekeeping success score.
1. Keep score to trend the occurrence of false positive and false negative gatekeeping decisions. I’d trend them separately. False positives lead to resource waste and opportunity costs. False negatives can adversely affect uptime and overall equipment effectiveness (OEE) and, in some instances, produce safety and/or environmental consequences.
2. Create taxonomies to standardize common notifications. This lets you leverage the repeatable nature of maintenance work. We have very few unique failures, so they can be standardized. ISO 14224 is a good starting point. The standard is oriented toward the petrochemical industry, but I have found that it’s generic enough to be broadly apply to other industries. A pump is a pump.
3. Creating a game plan to train, coach, and mentor your operators, maintenance technicians, supervisors and planners on the new taxonomy of maintenance notifications and new notification process. The technical aspects of improving the notification process are rather pedestrian in nature. The organizational-change-management aspects always present the greatest challenge you’ll want to manage this proactively.
4. Conduct “lean-cell” plant walkdowns before STO events. A lean-cell is designed to deserialize a process. The inspect-to-work process involves many stakeholders and numerous hand-offs of the work package. Before a shutdown, assemble a group to include: 1) lead mechanical technician(s); 2) lead electrical technician(s); 3) lead operator(s) for the walkdown area; 4) maintenance and operations supervisor(s)/superintendent(s); 5) reliability engineers(s); and planner(s). Take your list of existing notifications and active requests on the lean-cell plant walkdown. Evaluate all notifications and work requests and make decisions working interactively as a group.
While you’re on the walkdown, keep your eyes peeled for other required work that might have been previously missed and for which no notification or work request exists. Also, you can refine the priorities assigned to remaining work, which is really important. I’ve personally had great success leading these lean-cell walkdowns. It’s not uncommon to cull a sizable percentage of the previously approved work. If you’ve never conducted a lean-cell plant walkdown prior to a STO event, give it a go. You’ll love the results.TRR
ABOUT THE AUTHOR
Drew Troyer has 30 years of experience in the RAM arena. Currently a Principal with T.A. Cook Consultants, he was a Co-founder and former CEO of Noria Corporation. A trusted advisor to a global blue chip client base, this industry veteran has authored or co-authored more than 250 books, chapters, course books, articles, and technical papers and is popular keynote and technical speaker at conferences around the world. Drew is a Certified Reliability Engineer (CRE), Certified Maintenance & Reliability Professional (CMRP), holds B.S. and M.B.A. degrees, and is Master’s degree candidate in Environmental Sustainability at Harvard University. Contact him directly at 512-800-6031 or dtroyer@theramreview.com.
Tags: reliability, availability, maintenance, RAM, planning and scheduling, work prioritization, false positives, false negatives, change management

